Build an AI-Native Organization
The next wave of winners aren't the companies that use the most AI — they're the ones who weave AI into the fabric of their organization. Business, ops, engineering, support and leadership collaborate on the same board. AI stops being one engineer's private plugin and becomes the productivity of the whole company.
AI-Native isn't a tooling upgrade —
it's an org upgrade
You don't need to hire 50 more engineers or run another round of "company-wide AI training." You need to weave AI into how your organization actually collaborates — business launches requests directly, AI picks up work behind every role, and leadership sees the whole picture on one board. Below are four key organizational upgrades.
Skip the hiring spree — equip your team with agents
Code Agent ships code, Data Agent runs analyses, Browser Agent gathers context — every card on the board is a dispatched virtual teammate. A 30-person team delivering 100-person output isn't a slogan; it's a count of cards moving through your board.
Business stops waiting on IT scheduling
Business, ops and support drop one-line requests on the same board; AI agents pick them up on the spot. IT stops being the scheduling bottleneck and becomes the governor — defining rules, agents and acceptance criteria. Cross-team waiting and Slack pings vanish.
Org-wide AI-Native, zero learning curve
Support, sales and leadership don't need to learn an IDE, write SQL or memorize commands. WinClaw lives in chat — one Chinese / English sentence and it's done. The hidden tax of "AI training" is gone. Roll out today, the whole company is on board tomorrow.
The leadership control tower
Which boards are alive, who's executing, this week's org-wide AI throughput, AI time-spend invoice, security audits — all in one dashboard. AI stops being a black box: every card is a dispatchable, traceable, reversible, billable unit of work.
We'll help you map the top 3 roles in your org that should go AI-Native first
All people + all agents
on the same workbench
A Vibe Coding tool's retention curve is its model vendor's spokesperson. We build something different — a collaboration model where business, ops, engineering, support, plus Code Agent / Data Agent, all live on the same pipeline. Model churn doesn't break it.
Roles × Agents · Collaboration Matrix
Each cell is a 'role + agent + board contract' running on the same pipeline
Drop one sentence, board auto-creates a card → Code / Data Agent picks it up
Pin an analysis card → Data Agent runs SQL, ships the report, writes back to the card
Review Data Agent output, fine-tune metrics → auto-report + human edits ship as one
Review Code Agent commit, append acceptance criteria → Agent self-verifies + human approves
Forward a customer screenshot → board auto-creates a card and routes to the right agent
Global dashboard: which boards are alive, who's executing, this week's org-wide AI throughput
What we are NOT selling
Not an IDE plugin
Cursor / Copilot sell 'making the model feel smoother'. We sell 'making the entire org speak the same collaboration semantics'.
Not a model wrapper
What you pay a tool company is mostly the model API. Model changes, vibe changes. Our collaboration semantics decouple from any specific model — swap models, swap agents.
Not just another kanban
Trello / Linear / Vibe Kanban are task managers. Our board is a contract: role + acceptance + instance + judgement reason.
Moat · Why model churn won't wash this away
The companies that win the next wave aren't the ones using more ChatGPT — they're the ones that actually rewire the org around AI-native collaboration.
It's not another Trello — it's a contract for every role and every agent
Each card carries role + acceptance criteria + bound instance + execution mode + judgement reason. Code Agent ships frontend tweaks, Data Agent runs cohort SQL — same board, same semantics, every time.
The life of an issue · from idea to ship
Humans own the requirement, AI owns the execution — clear roles, steady rhythm
Humans manage the requirements
You focus on what to build — shape goals, rank priorities, judge outputs. Leave the how to the agents and spend your cognitive budget where it matters.
AI executes reliably
Every card is a dispatchable, traceable, reversible task. Agents actually run code on the instance you bind. Execution traces, logs, and artifacts are all preserved.
A real software pipeline
Requirement → Dispatch → Execute → Review → Merge. Every step is standardized, observable, and parallelizable. Software development finally enters the industrial age.
Upgrade software engineering from craftsmanship to industrial production
Learning cost is the hidden tax
of going AI-native
WinClaw is your AI-PC assistant + WeChat channel. Business, ops, support and leadership don't need an IDE, SQL, or CLI commands — one Chinese / English sentence in the WinClaw chat or WeChat triggers board dispatch, data queries and agent runs.
One sentence, dispatched to the right agent
Dispatch path
Your laptop does the work, you code from any browser
Start auto-coder.chat.lite on your work laptop and connect it to the cloud. Then open auto-coder.chat on any phone, tablet, or browser — your instance list shows up and you can drive real project work on the remote laptop, as if you were sitting in front of it.
Start the lite locally
Run auto-coder.chat.lite in your project directory. Your laptop hosts the environment, code, and models.
$auto-coder.chat.liteConnect to the cloud
Run /connect with your Cloud API Key — the instance opens a persistent connection to auto-coder.chat and goes online instantly.
$/connect ak_xxxxxxxxxxxxDevelop from anywhere
Open auto-coder.chat on any device, see the list of your connected projects, jump in and chat, edit, dispatch tasks — exactly like a local terminal.
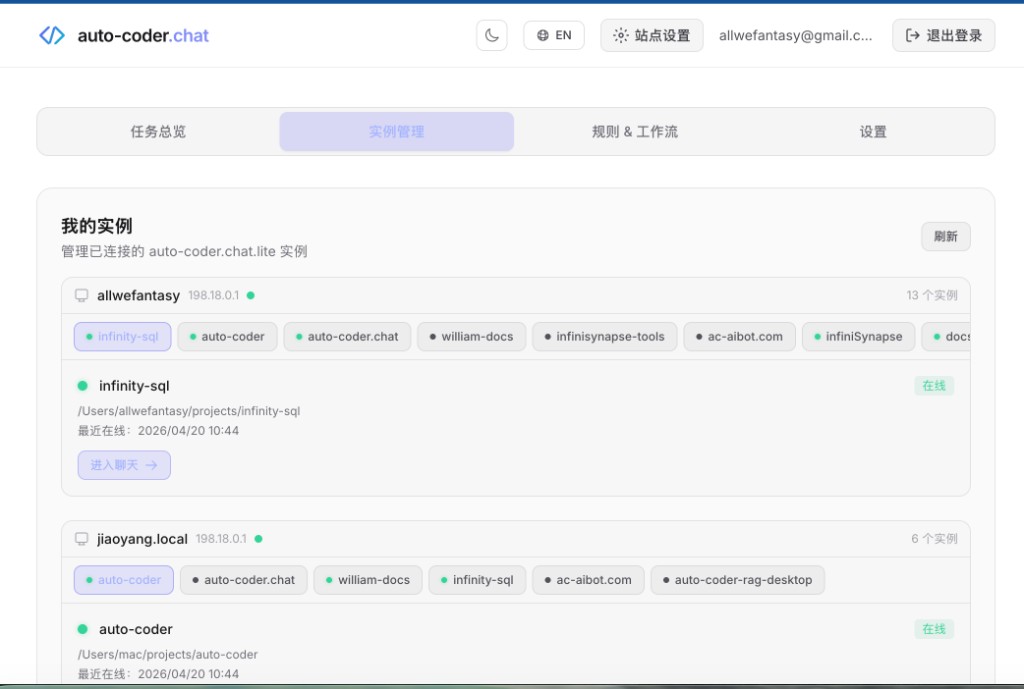
Sign in to auto-coder.chat and see every connected project grouped by host with live status.
The engine behind remote development
Every instruction you send from the browser lands on your laptop via SubAgents multi-model collaboration — put the right model on the right task, keep token cost at 1/10, even remotely.
Auto Mode
RecommendedAI autonomously decides when to dispatch SubAgents, how many to use, and what each handles. Install one rule and start coding — no manual orchestration needed.
- Zero config, works out of the box
- Ideal for most daily development tasks
- Smart multi-model routing, auto cost optimization
Cowork Mode
AdvancedDefine multi-agent collaboration workflows via YAML — break complex tasks into multi-stage DAG execution with precise control over models and strategies at each phase.
- Custom multi-agent collaboration pipelines
- Supports async background execution
- Ideal for large-scale refactoring and fixed processes
5 tasks take 18u in series, 5u in parallel
Concurrency built on git worktree — every SubAgent gets its own branch and runs truly in parallel. Toggle below to benchmark serial vs async timelines, throughput, and token waste, live.
Live Gantt · Serial vs Async
X-axis is time units. Each colored bar is a task. Toggle the mode to compare schedules.
Time comparison
Total wall-clock time inferred from the Gantt above — shorter is better.
Branch conflicts are handled by an auto-merge strategy. Failed tasks can be re-run in place without affecting sibling branches.
Geek stack
Interface Preview
Dual Terminal modes: classic auto-coder.chat and lightweight auto-coder.chat.lite
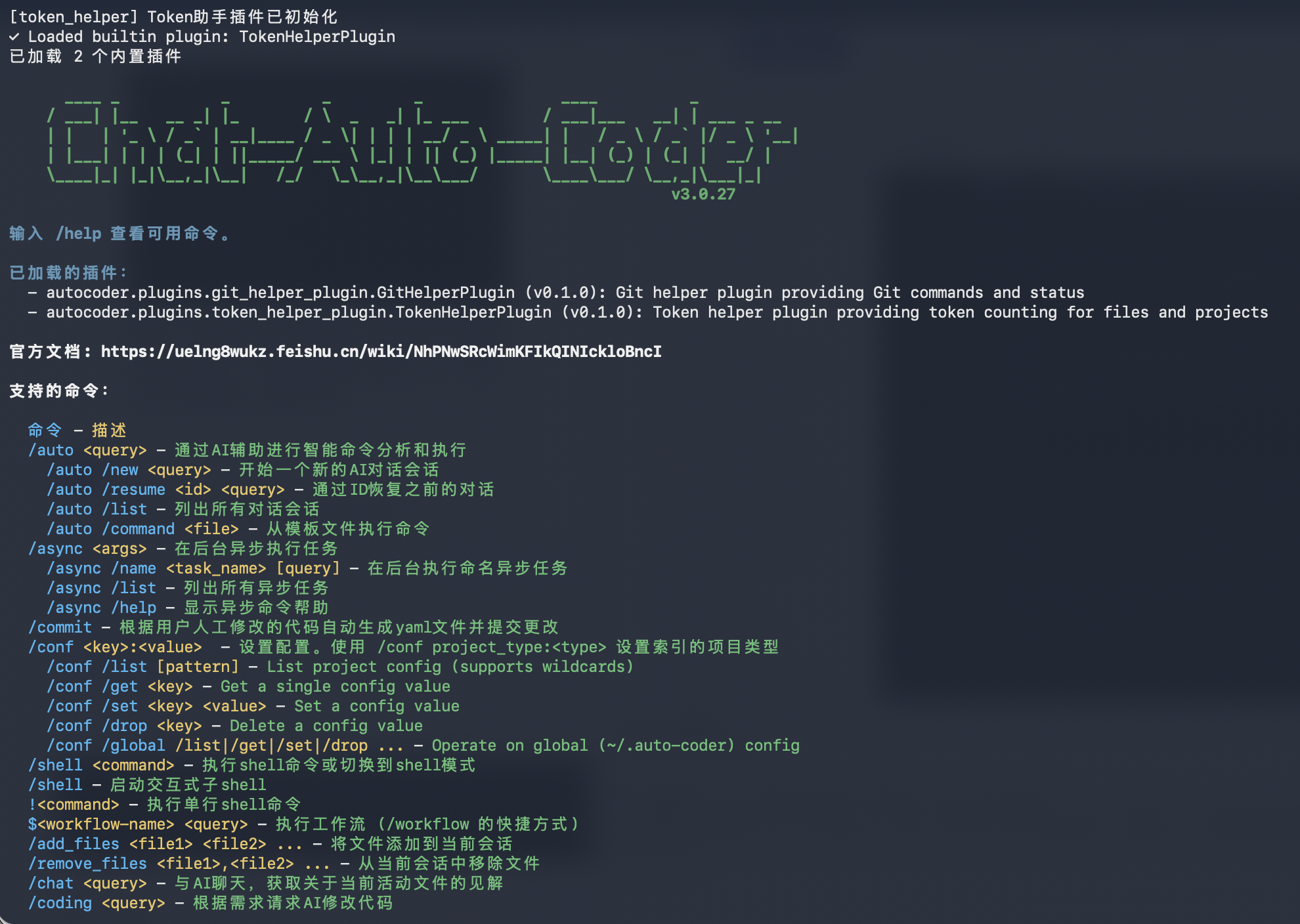
Classic Terminal: auto-coder.chat
Full command system and advanced capabilities for deep engineering workflows.
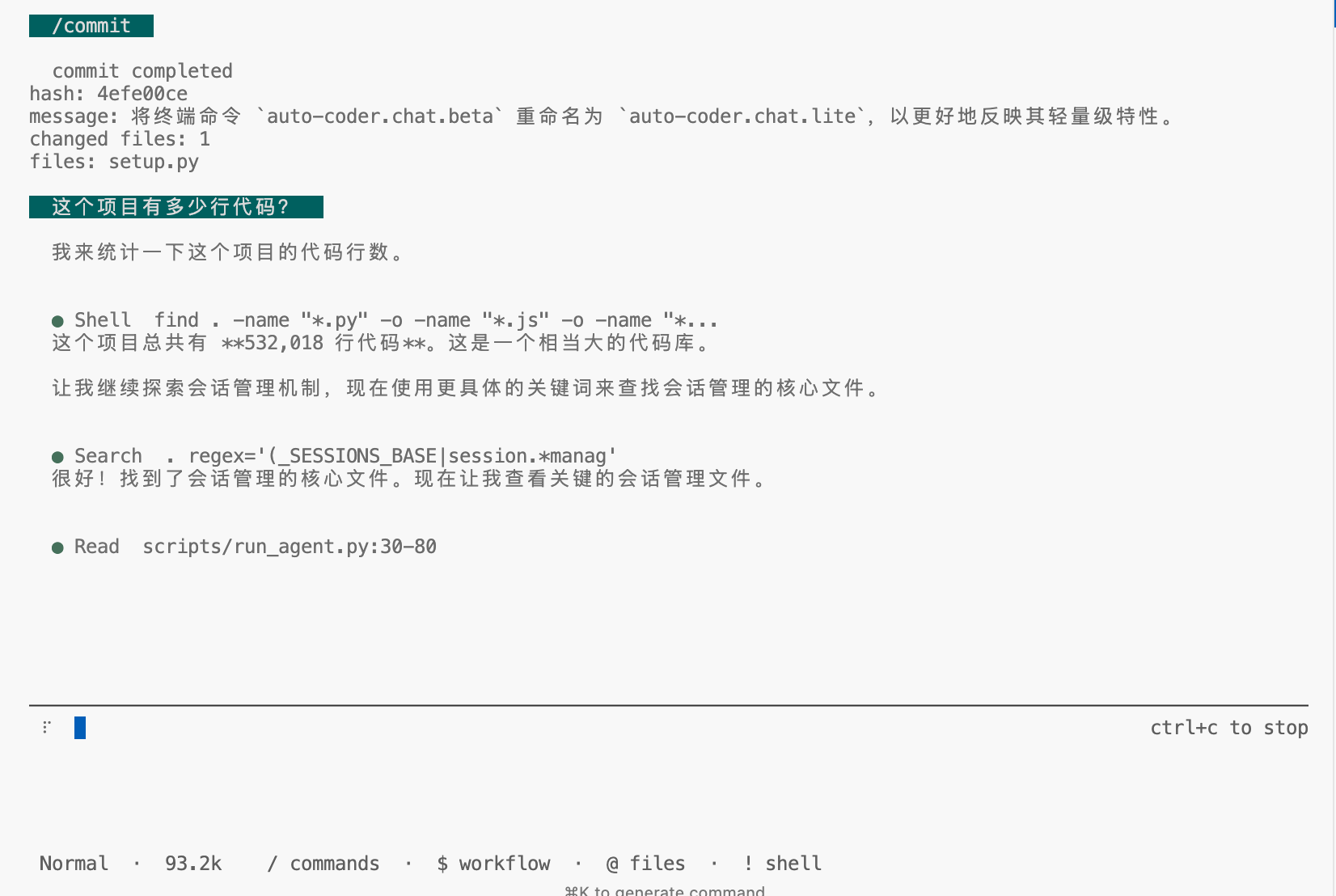
Lightweight Terminal: auto-coder.chat.lite
Simpler interaction and lower onboarding cost for quick start and daily coding.
 Claw Friendly
Claw Friendlyauto-coder.run Headless Mode
A headless CLI for scripted and non-interactive execution (alias: auto-coder.cli), ideal for Claw integration, CI pipelines, and batch tasks.
Recommended Invocation
Put prompts in files and pass them via --from-prompt-file, then use --verbose and --output-format stream-json for traceable, machine-readable event streams. Turn on --async when you need parallel task splitting.
auto-coder.run --from-prompt-file task.md --verbose --output-format stream-jsonecho "task" > auto-coder.run --verbose --output-format stream-jsonReady-to-use Tool Market
Official tools spanning document processing, browser automation, IM bots, scheduling, and AIGC. One command to download and install.
Get Started with auto-coder.chat
Four steps to SubAgents-powered remote AI coding
Install
python3 -m pip install -U auto-coder auto_coder_webNote: Python supports versions 3.10 - 3.12 only
Start auto-coder.chat.lite
cd your-projectauto-coder.chat.liteConnect to Cloud
/connect ak_xxxxxxxxxxxxCreate a Cloud API Key in the auto-coder.chat dashboard and replace ak_xxx
Develop from Anywhere
Sign in to auto-coder.chat, open My Instances, click into any connected project to chat
Capabilities at a glance
Everything above, distilled into a single cheat-sheet — for a quick review or to share
Remote Dev, One-Command Cloud
Run auto-coder.chat.lite on your laptop, /connect to the cloud, and drive every project from any browser — your code and models never leave your machine
Async Vibe Coding
Built on git worktree as core infrastructure — multiple tasks execute truly in parallel with automatic conflict resolution, no serial waits or manual merges
Controllable AI Duration
Precisely control AI runtime via the /time parameter, giving the agent sufficient time to think and iterate for higher-quality code output
Unlimited Context
Run sessions over 800k tokens using 128k/200k context models with intelligent chunking
SubAgents Multi-Model Cowork
The engine behind remote dev — route routine tasks to cost-effective models and reserve premium models for critical decisions to keep token cost low, even remotely
Domestic Model Support
Support for domestic model coding plan subscriptions including GLM4.6 and M2